In the last few months, we’ve been busy adding a whole new set of amazing features that will be available in the next release of SmartClient and SmartGWT.
We have already announced some fantastic additions to the framework in our previous posts (Part 1 / Part 2 ), and now there’s even more to extend the power and flexibility of SmartClient and SmartGWT!
This post shares just another taste of some of the new enhancements we have made recently.
FacetChart Databindingand Improvements
Historically, Charts have had their data values set by using the SetData() and updateData() APIs to set a static view of the chart.
In release 13.0, we’ve enhanced FacetChart to be a DataBoundComponent. The new features support a fetchData API that takes criteria and other DSRequest settings (like sorts), just like grids do, and will perform local filtering of data if criteria changes. So you can now easily create a drill-down interface that doesn’t require server contact.
OpenFin enables you to build multi-window desktop apps that look and feel just like natively installed apps so you can maximize your desktop real estate. Your windows can sit anywhere on the desktop, with or without frames. Apps you don’t actively watch can be minimized and automatically pop up when needed.
In collaboration with one of the world’s largest banks, our support for OpenFin means you can now create desktop applications that can open windows on multiple monitors.
Sharper Imagery
We’ve massively improved the quality of our internal imagery, so no matter how much you zoom in, you’ll still get the crisp, clean, seamless image view that you need.
SplitPane AutoNavigate
SplitPane component just got smarter. Using an “Auto-navigation” approach, SplitPane analyzes the controls placed in each pane and the DataSources they are bound to. It then automatically navigates between panes at the right time based on the actions that you take.
If you want to see what’s available in V13.0, download the V13.0 Pre-Release from our Downloads page.
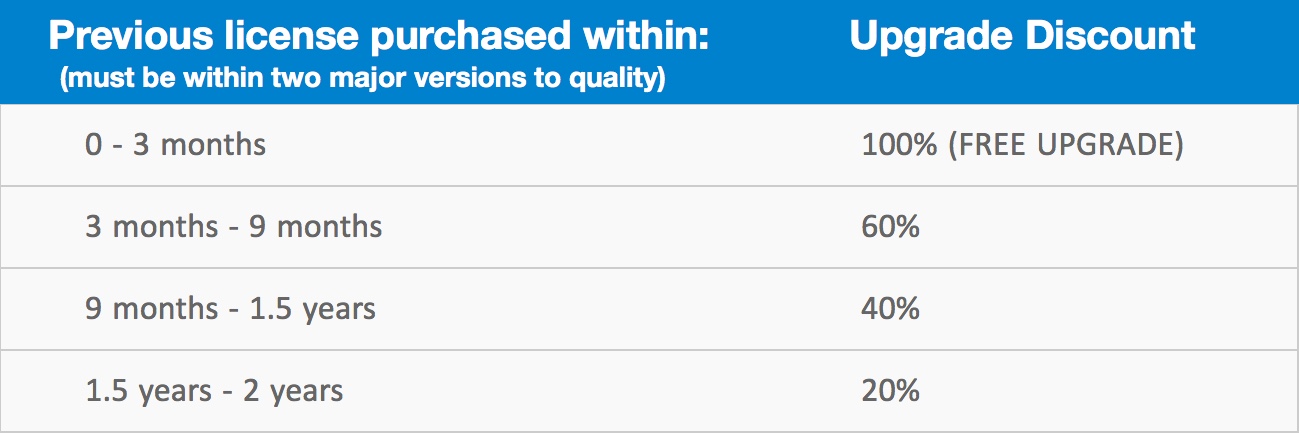
If you want to upgrade early to V13.0, upgrade discounts are available based on your last license purchase date. View our License FAQs for more details, or contact us to discuss your upgrade options.
We are proud and pleased to announce that V13.0 of SmartClient and SmartGWT is officially here, with tons of fantastic new features. We’re sure you’ll agree it was worth the wait.
Some of the great features we have added to V13.0 are:
Once you have purchased your upgrade, Download Release 13.0 to get started (don’t forget to log in first)!
As always, please send us any bug reports or feedback in the Forums. Please be clear about what product and version you’re using when reporting issues, including the exact date of the build.
Last week we talked to a Principal Scientist (let’s call him Ken) at one of the worlds largest pharmaceutical companies. Ken gave us some really great insight into why and how they use SmartClient.
Ken’s organization provides software support (at varying levels) for thousands of in-house scientists scattered across “innumerable areas of expertise and roles”. Scientists come to his group when they need customized or unified solutions from software developers with domain knowledge.
The web applications that Ken’s team writes are obviously used by people who are highly educated. Their time is precious and their patience low. They demand “solutions that are highly sophisticated“, and they have “uncompromised expectations on ease-of-use.”  They “have many ideas, theories, and hypothesis that they want to explore”, so there is a long list of web applications to be developed, and also a long list of feature requests raised as their hypothesis unfold. Their work also generates and requires analysis of “huge volumes of data“.
For Ken, these demands meant he needed a platform that:
Can handle volume data from both performance and a usability perspectives
Has intuitive, high productivity UI components
Supports rapid development of web applications
Ken’s Results
With several years experience using SmartClient, Ken said:
I really like Smartclient because I can create new solutions quickly and then easily adapt to userâ€s feature requests as they evolve because itâ€s usually only a matter of re-configuring how Iâ€m creating Smartclient objects. I donâ€t need to be too careful about collecting all possible use-cases up front because when they come to a new understanding of their own expectations, I donâ€t need to tell them that weâ€d need to change technologies to deliver their new ideas.
ListGrid, FormItem, and DynamicForm are the key widgets I turn to.
I also highly value the support forum. I imagine that my needs which are sometimes off the beaten track, so I highly value the rapid turnaround on enhancements, bug fixes and/or suggestions.
Here are just a few of the solutions Ken’s team built this year (note that all of these are leveraging our new ‘Tahoe‘ skin):
#1 Bulk Data Handling – “PPB Editor”
The “PPB Editor†(you can think of it as an electronic lab notebook) was written to enable scientists to rapidly load bulk data into a 3rd party data storage solution. The 3rd party had provided their own GUI, but it was too tedious to use at the scale the scientists required. It also didnâ€t match the scientistâ€s workflow. Furthermore, by writing their own interface, they have a convenient place to implement their own business rules (e.g., “autocalculators†and validation) to help people conform the raw data they collect to expectations set by the business and to support analytics. In particular, SmartClient helped with the following:
Binding to Datasources extremely quickly
ListGrid Expanding rows capabilities to allow additional information to be accessed without adding an unmanageable number of columns
FormItem was also a key feature — particularly since a class can be defined once and reused in both ListGrid and DynamicForm contexts. This meant that in their bulk editor, they can leverage multiple widgets to update the same data – saving much development effort and providing the scientists with the optimal UI.
The “Mylo†tool is for analytics — to help scientists find and/or explore new design ideas with experimental data previously collected. This application required the depth of functionality offered by SmartClient components. The following were critical:
The “Plate Layout†tool came about when a scientist described an upcoming technical challenge to Ken. Ken then created a GUI in less than one day that the scientist could use to test a hypothesis.
For Ken, the ability to rapidly develop web applications makes SmartClient indispensable in the pharmaceutical research and development environment.
Developing IT solutions to support research for new, more effective and efficient treatments for heart and lung disease.
Royal Brompton & Harefield NHS Foundation Trust is a partnership of two specialist hospitals, known throughout the world for their expertise, standard of care, and research success. Â RBH has achieved incredible things: performing the first successful heart and lung transplant in Britain, implanting the first coronary stent, and pioneering intricate heart surgery for newborn infants. Countless lives have been saved, diseases prevented and lives extended.
However, the technical support for the research process was – until more recently – ad-hoc and inconsistent. Research data was often collected on paper and rekeyed into spreadsheets, or stored in one-off databases. This led to manual labor processes, data availability delays, and data accessibility problems. Analysis was also difficult and inefficient as data was stored in disparate locations, and a lack of tools necessitated custom SQL reports to be written.
Steven Collins is the IT lead at CRC (Cardiovascular Research Centre). With Smart GWT as the core technology, Steven and his team his team has made huge improvements. To highlight just a few:
Leveraged the rich Smart GWT validation features to prevent all mistakes during data entry
Used the DataSource XML Generator to combine data across studies, and with patient information as it is captured over time
Empowered researchers (via Dynamic Data Filtering) to create very complex queries (e.g. tree / nested, and, or, not) directly through the UI – without having to learn SQL.
Steven’s latest solution at CRC is the ‘Cardiovascular Research Centre Database Internal Web Portalâ€. It makes available all research data from all projects, available through a web portal. The CRC has many research studies going on at any given time, and data gathered in one study can actually be useful in others. Combining data across studies, and with patient information as it is captured over time (for example, medical events, doctor visits and reports) has provided invaluable insights into ongoing benefits and outcomes of treatments.
Learn how Steve and his team at Royal Brompton & Harefield NHS Foundation Trust have leveraged Smart GWT to achieve all this and more.
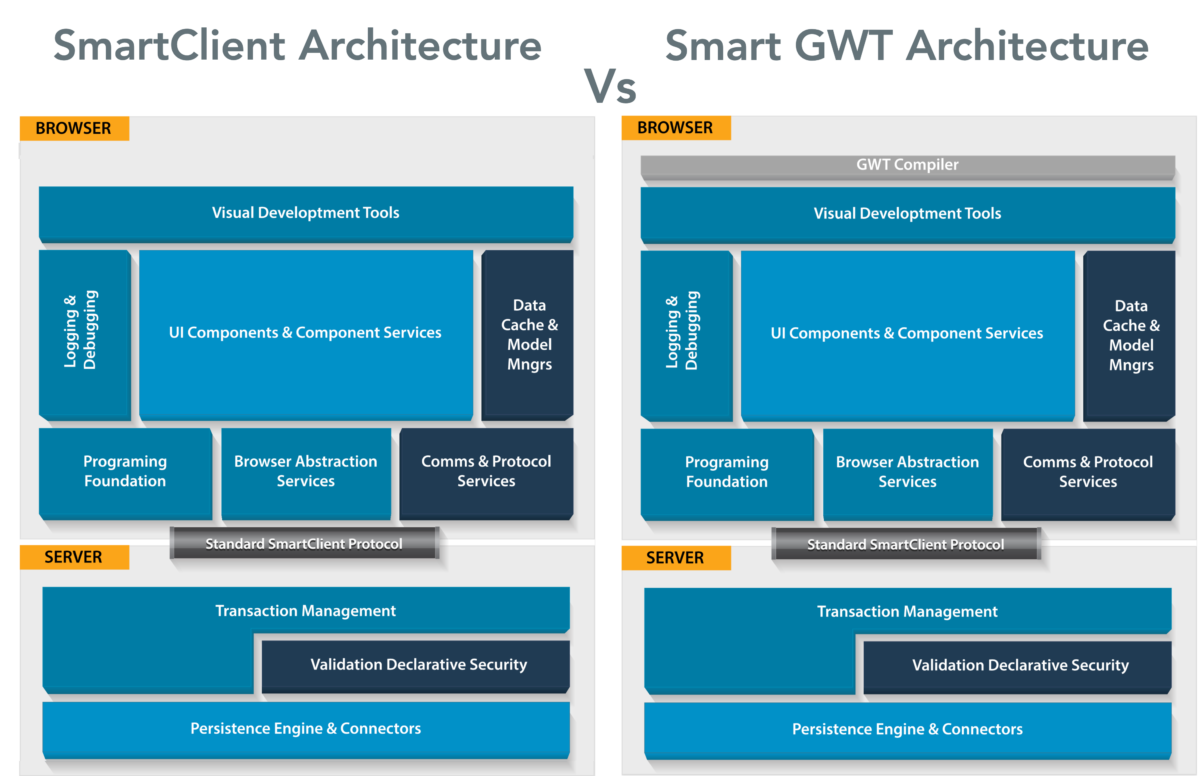
We often get asked about the difference between SmartClient and Smart GWT. The answer is: ‘not much‘.
When you’re running SmartGWT, you’re also running SmartClient
When you are running SmartGWT, you are also running SmartClient. You are using SmartClient’s widgets, data binding, browser compatibility, etc. See the SmartClient vs SmartGWT architecture diagrams below:
As you can see, we only use the tiniest sliver of GWT – just the GWT compiler. The GWT compiler translates your application code to JavaScript, and your translated application code then calls SmartClient APIs.
With the management of GWT transferred from Google to a “Steering Committee”, and the lack of a GWT release in the past couple of years, we get asked a bunch of questions about the long term impact of GWT on Smart GWT. Will we keep developing Smart GWT? Will Smart GWT continue to support the latest browsers? etc.
What happens with GWT is irrelevant to Smart GWT
The fact of the matter is that what happens with GWT is irrelevant to Smart GWT. The problems that people anticipate from core GWT development slowing down do not apply to people using SmartGWT:
if the pace of widget development in GWT slows down, doesn’t matter: SmartGWT’s widgets will continue to be rapidly improved
if GWT widgets stop supporting the latest browsers, doesn’t matter: SmartGWT’s widgets will continue to support the latest browsers
if GWT’s recommend data binding approach continues to change radically with new releases, doesn’t matter: you’re using SmartGWT’s data binding
We literally cannot help but continue to improve SmartGWT
We also get asked: will Isomorphic stop emphasizing SmartGWT, and focus more on SmartClient? This also is a non-issue, because, the way we develop new SmartGWT features is that we develop new features for SmartClient, and then an automated process takes the new SmartClient documentation and generates new SmartGWT APIs from it. So we literally cannot help but continue to improve SmartGWT, as we build more SmartClient features.
We are excited to share with you some of our upcoming features due to be launched in V13.0 of SmartClient and SmartGWT.
Open API Support
Integrating with other technologies just got a lot simpler!!!
We’ve always made it pretty simple. If you’re using our technology, whenever you define a DataSource, we automatically provide a REST-based interface to it. This means you can easily integrate with automated processes (such as reporting) or even provide access to third-party UIs (such as a native mobile applications).
Now, we’ve embraced Open API, which is an industry-standard way of describing server APIs, so you can access them with simple XML or JSON messages.
In 13.0, with no effort required at all, you can get a standard Open API descriptor explaining the REST interface to your DataSource. It’s available by simply appending openapi.yaml to the URL where you have registered your RESTHandler servlet.
The Open API descriptor is quite rich, incorporating your field types, validator definitions, and other standard DataSource metadata to provide a complete descriptor.
Your customers will be able to use Open API tools to get connected faster than ever!
Modern UIs going for the “minimalist” look often have scrollbars that aren’t even shown until you start scrolling, which nicely reduces “visual noise”.
Now in 13.0, we automatically detect if your browser hides scrollbars by default, and we match that behavior.
If you’re a big fan of our custom scrollbars – which are designed to match the skin you’re using – don’t worry! You can reverse this change with a single boolean setting autoHideScrollbars.
To give you an idea of how this looks, take a look at our new Reify tool with and without scrollbars – much cleaner!
See how the scrollbars come into view and are manageable as soon as you need them!
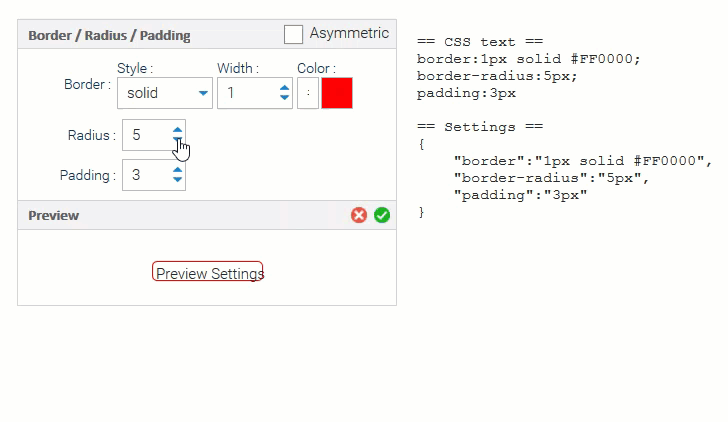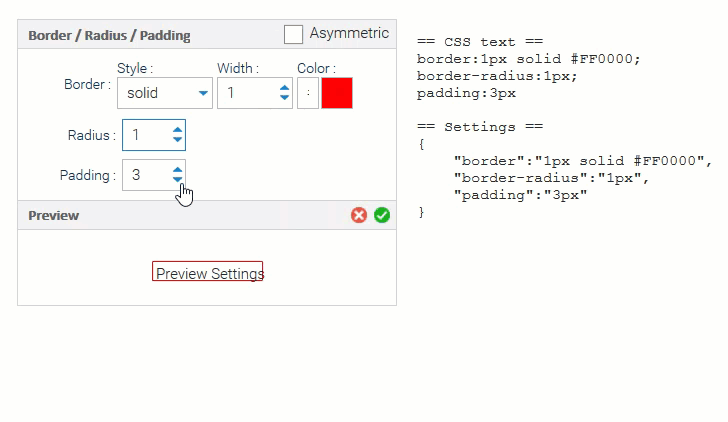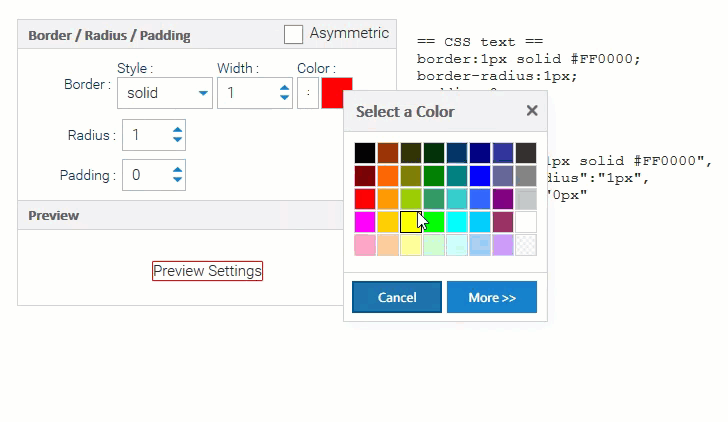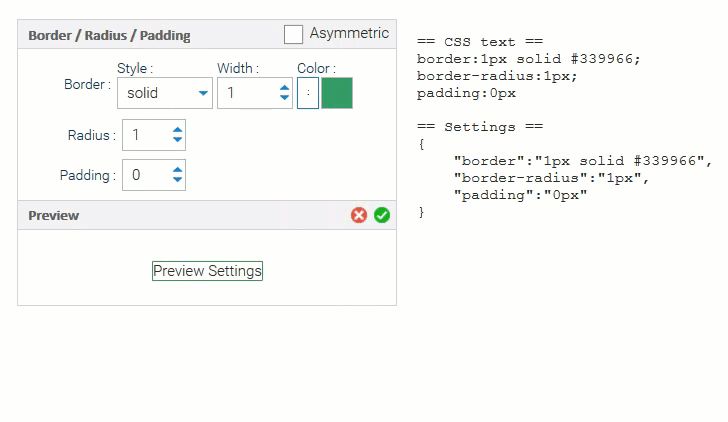
CSS Editors Your end users can now customize the look & feel of applications you deliver!
Our platform is often chosen because it is so flexible, and people want to offer their end users extreme customization options: everything from saving dashboards full of deeply customized grids, to the ability to create queries that only analytics platforms can usually do.
In that spirit, we are introducing powerful tools for editing the appearance of applications:
Our StyleEditor lets you edit all the basics of a CSS style: colors, borders, padding, fonts, etc
Client-side Authentication & Roles Simulator for Prototyping
The server team hasn’t set up authentication and roles yet, so there’s no way to test that stuff, right?
Wrong!!!
Similar to Client-Only DataSources, we now offer a Client-side Authentication & Roles system.
You just call client-side APIs like Authentication.setRoles(), and then:
DataSources will disallow operations if you don’t have the role (set via operationBinding.requiresRole)
Component fields that should not be visible won’t be (set via DataSourceField.editRequiresRole for example)
UI components that should disappear or be disabled based on roles can declare this (via button.visibleWhen for instance)
Then, when you have a real authentication system, you just make the call to setRoles() with the real set of authorized roles and everything just works with no code changes required.
This is just another way that Isomorphic helps you create great parallelism between your UI team and your server team, so your projects are delivered early! Take a look at the sample here.
This system also makes it easy to test client-side security rules in isolation, so you can rapidly figure out where the bugs are.
Finally, a quick note: obviously this system is not for actually enforcing security – that needs to be done on the server. However, the settings noted above, requiresRole, also perform the actual enforcement when used with our server framework, in a server DataSource descriptor (.ds.xml file).
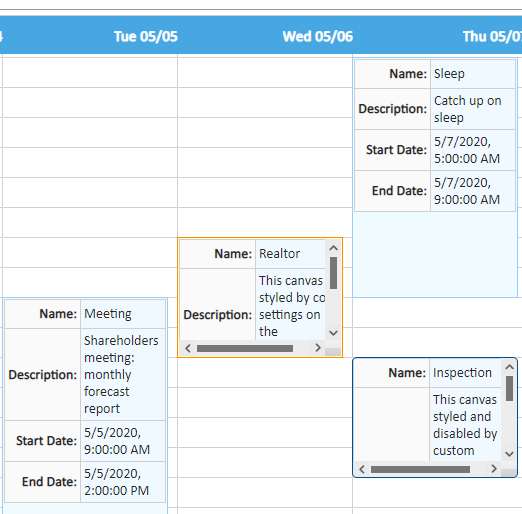
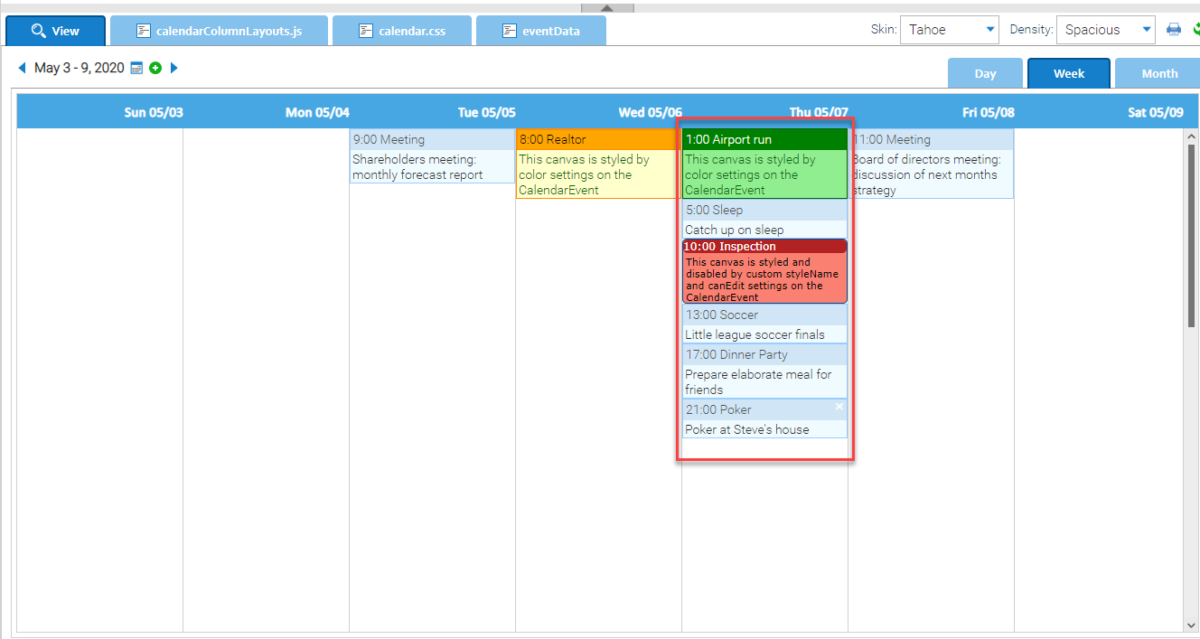
Custom Event Widgets for Calendars
The Calendar component can now show an arbitrary UI component instead of the built-in events. You can make your events interactive, or allow them to be edited directly instead of in a pop-up dialog by making use of showEventCanvasComponents.
No matter what content you want to create, (Links to other URL’s, imagery, grids and/or forms), they can all be embedded in a calendar event, making calendars flexible enough for any features you will ever need!
The calendar has also gained a new layout mode: events can be stacked within days rather than being rendered at specific times on a day. This allows the Calendar to also function as a kind of “to-do” list, where events are associated with a day but not with a particular time slot.
This is just a taste of some of the powerful new features that will be available in V13.0 Keep an eye out for more about what’s coming up in our next major release.
If you want to take a look at what’s available in V13.0, download the V13.0 Pre-Release from our Downloads page.
If you want to upgrade early to V13.0, upgrade discounts are available and are based on the date of your last license purchase. View our License FAQs for more details or contact us to discuss your upgrade options.
Following on from our last feature post for V13.0, welcome to our second installment of even more fantastic capabilities that will be available in the next release of SmartClient and SmartGWT.
Persistent Hovers
Sometimes, a hover is so useful you want it to stick around!
Now, you can just use the focusHoverKey setting to provide a keyboard shortcut for a user to “stick” a hover in place. The hover becomes a floating window that the user can interact with or dismiss.
Improved Client-Only DataSource
Client-Only DataSources provide an efficient way to prototype the UI while the server-side guys are still working to get things going. When you build a UI that uses Client-Only DataSources, you can swap in the real DataSources when they are ready, and nothing about the UI needs to be changed – it just works.
Now in 13.0, Client-Only DataSources have “grown up” to be able to mimic all of the powerful features of our server-side framework. You can now:
Define relationships between clientOnly DataSources with the foreignKey attribute
Use includeFrom to pull values from related DataSources, the equivalent of a SQL JOIN
Use aggregation features to compute sums, averages, maxes or distinct values – like SQL’s SUM, GROUP BY and SELECT DISTINCT
Use aggregation even with related DataSources, for use cases like getting the total cost of all items that are related to an order
Basically, all of the Server Summaries features discussed below now work with ClientOnly DataSources.
Server Summaries Enhancements
Our server framework can do advanced aggregation from just simple declarations, and can even do it on the fly!
A series of new samples demonstrates the power of aggregation and ways to customize it.
The DynamicProperties system allows you to declare that a component setting depends on data in surrounding components, including user-entered data.
With this new support, there are now literally thousands of boolean settings on components: anything from listGrid.showFilterEditor to comboBoxItem.allowEmptyValue, that can be succinctly declared to depend on user-entered data, without having to write event handling code.
In this example, you can see a form for configuring an export for a grid. There’s no code, no event handling, anywhere in this sample – it’s all done via simple declarations, and easy for a non-programmer to understand.
TIP: You can already declare whether components are visible, enabled, or editable via the visibleWhen and enabledWhen properties.
Adaptive Forms It’s now much easier to design a form that works well on both desktop and mobile!
Just design your form with the desktop in mind, and turn on the new “linear mode” for mobile.
In linear mode, your form will render with one form control per row, ignoring all the size & placement settings that are typically used when designing a multi-column form for desktop use.
If you still want to tweak your form for mobile – for example, you have two very short text fields that can appear adjacent, even on a narrow phone screen – you still can. You use the same settings you usually do, but prefix them with linear.
For example, startRow -> linearStartRow.
Take a look a the full sample to see how we do this.
Infinite Scroll Repeating Components
Our grids allow you to place any kind of component you want into cells or rows, including completely replacing the default row rendering. This is an extremelypowerful feature that allows you to use a grid to contain any kind of repeating widget, for any size of data.
Check out this new sample, showing a specialized rendering of each row, including a non-columnar data layout, the ability to edit data, and actions that are enabled or disabled based on data values in the row.
It doesn’t even look like a grid! But you have all the power of the grid, with a completely different presentation for rows.
If you want to take a look at what’s available in V13.0, download the V13.0 Pre-Release from our Downloads page.
If you want to upgrade early to V13.0, upgrade discounts are available and are based on the date of your last license purchase. View our License FAQs for more details or contact us to discuss your upgrade options.
As Isomorphicâ€s CTO, Iâ€m typically brought in to save projects that have gone off the rails. So Iâ€ve got 20 years experience in vigorous facepalming.
Very often, we are approached by companies that started with another technology and have hit a dead end. Typically, we end up inserting our more sophisticated components into the middle of existing screens, and then the customer migrates to our technology over time, slowly, painstakingly cutting through the spaghetti code they had to write because they didn’t start with us.
Whenever this happens, I always try to figure out how the customer ended up using some other technology rather than starting with ours.
Sometimes, they just didn’t do an evaluation at all. People blindly follow trends, and developers are just as guilty of this as anyone else.
However, sometimes, we run across a customer that did evaluate our technology, and decided against using it, only to regret that decision later.
This happens because people evaluate software in the wrong way.
I’ll explain what I mean with a story.
Let’s say you are trying to figure out which vehicle would be best to use when entering an endurance race.
As a first step, you try to figure out if you can get the vehicle to go 20 feet. A reasonable first test, right? Clearly a vehicle that can win an endurance race must be able to go 20 feet with ease.
So here are the two possibilities you’re evaluating:
the vehicle that won Le Mans last year
.. or ..
a tricycle
After testing them out, you determine that both can go 20 feet. However, the vehicle that won Le Mans gets poor marks because:
You had to find the keys
You had to open the car door
You had to turn the key to start the engine
You had to shift into gear
It wasn’t obvious which pedal to push to go
So clearly, the tricycle is the better choice for Le Mans, and the next step is to commit to the tricycle and see how fast and efficient it can be made.
Except, obviously not, right?
So what was the mistake?
The mistake was: you didn’t test whether the vehicle could do well in Le Mans, you tested whether it could go 20 feet.
And if the task is going 20 feet, then a tricycle looks pretty damn good, because in general, a technology is going to look really good when it’s doing the most that it was designed to do, and is going to look not as good if it’s asked to do something that’s a little too simple.
Now you may be thinking: that’s ridiculous! No one makes decisions that way.
Ah but they do. It’s just that, when evaluating software, things are more complex, and it’s not as blindingly obvious that you are comparing a race car to a tricycle.
Here are a few real-life stories of competitive evaluations where our technology “lost”, only to have the customer come back to us later:
Comparing grids by connecting to a rudimentary data service
Multiple times, we’ve had evaluators try to compare grid components by connecting to some kind of free public data service, or to a data service created as a tutorial. Invariably, these services are very basic: they don’t support paging, advanced use of criteria, sorting, editing of any kind, or any other advanced features, even though the final application will definitely be using such features.
In this type of evaluation, our technology is made to look bad because you have to turn a bunch of features off to deal with such an underpowered service, and because you have to adapt to a poorly designed protocol that is not built for an enterprise UI.
As a result, the final UI is about the same with either technology, because, again, they turned all the good stuff off. Since our technology was a little harder to set up, the simpler and less capable technology is chosen. Later, the customer realizes that they really do need those advanced features, and it would be a nightmare to try to rebuild them based on the simpler technology. And that’s when they call us back.
Building a Login Dialog
This evaluation is flawed first of all because our best practices tell you to use a plain HTML login page. This allows you to begin caching your application while the user is logging in. We even provide such a starter login page, complete with caching logic.
But the bigger issue with this evaluation is that it’s too simple. Form components for enterprise apps are distinguished by their advanced layout behaviors, advanced data-binding support, and wide range of controls (like our date range editors).
The login dialog is the one place where none of these features are useful: you pretty much have the entire screen for two simple text fields, and data-binding doesn’t apply.
Instead, this evaluation should have focused on building a typical form for a business application, complete with complex validation rules, typeahead and other productivity features. Then, they would have found that, with our technology, everything is already set up how you would want it, and we have made the hard things really simple.
Focusing on replicating a “pretty” design
People like UIs to look good, and in a demo of UI components, one of the easiest ways to look good is to create a very “spacious” design, where controls are oversized, a huge amount of padding is used, and enormous, attractively-styled error messages appear in the middle of the form layout, right under the item that has the error.
The problem here is that in enterprise apps, space is at a premium, and there are multiple panes and components on the screen all needing as much space as possible. The “oversized” look works for a simple web page, but not for an enterprise app.
Our platform correctly defaults to showing validation errors as just a compact error icon, which avoids misaligning typical two-column forms, and avoids creating scrolling due the form growing in size. In trying to match a design featuring oversized controls and gigantic error messages, the evaluator is trying to replicate an appearance which you do not want.
It’s straightforward to get the spacious look with our technology, for the rare case that it makes sense. However, in one example of this kind of botched evaluation, the design team worried that they might be “fighting” against our platform’s default look-and-feel choices, and went with another technology. They came back about 8 months later, having scrapped the old design after criticism of early prototypes, and began using our default look and feel with some customized colors and fonts.
Trying to apply CSS-based layout techniques
Extending on the above point, multiple evaluators have tried to copy CSS-based layouts from elsewhere, and found that this doesn’t work because our layouts are more than just CSS. CSS-based layouts simply cannot do what our platform can do, in terms of features like Adaptive Width (sample).
So called CSS-based “mobile adaptive” frameworks simply switch to a completely different layout for smaller screens, rather than maximally taking advantage of screen space, as our platform can.
So here, a strength is perceived as a weakness, and the evaluator decides that a crude CSS-based layout system is the better choice.
In one instance, a few months later, a product manager called us up complaining that his developers were saying that certain layout behaviors were “impossible”, but he could see them right on our website! That ultimately led to switching back to our technology.
So how should you evaluate software like ours? Our advice is to take the most difficult and complicated screen you have, the one where you’re not even sure how to approach it yet, and try to build that.
Think about what it means that we would advise this. We are the real deal; we don’t take shortcuts and we don’t fake things.
And finally, what are the consequences if you make a mistake, and choose an underpowered technology? Your product designers are repeatedly told that certain features would take too long to implement, so the scope has to be reduced. After a painfully long and badly delayed development process, in which the developers repeatedly try to re-create features which are already present in SmartClient, finally a 1.0 version shambles out the door.
This 1.0 version is like the tricycle at Le Mans: some kind of engine has been bolted onto the side, which belches smoke and has a tendency to slice off limbs, and the tricycle must be ridden at low speed or the wheels melt!
Meanwhile your competitors, who used our software, entered the race months ago with sleek, flexible, blazing fast vehicles.
Don’t be on Team Tricycle – use the right tool for the job!!
About 10 years ago, I was working for a Fortune 500 company whose primary line-of-business application was built using a homegrown framework that was loosely based on a Java Model 2 / MVC type of architecture.
Iâ€d been asked to come up with a way to migrate away from that platform in phases and was looking at alternatives. We liked the idea of GWT at the time, and like many people, I found SmartGWT while I was evaluating various widget libraries. Right away, we were impressed by the depth and breadth of what the components could do out of the box (ListGrid comes to mind), but we pretty quickly realized that the server framework is equally powerful, if not more so.
At the time, Hibernate was considered the obvious choice for your persistence strategy, and a lot of people still feel that way. With respect, I think Iâ€ll just say that even proponents of Hibernate will ask you to invest in a pretty steep learning curve to understand how to use it properly, and then say that youâ€ll probably still have to write at least some (if not most) of your own SQL.
Frankly, I’ve never been convinced that any ORM solves the so-called impedance mismatch problem anyway. And where is the improvement when you still need to know SQL, and now also the entire ORM system and the challenges that come with it? In my experience, these projects typically end up adding redundancy, complexity, and as often as not, some performance issue. Ask your Oracle DBA how he feels about it.
With SmartClient / SmartGWT, I got complete, declarative control over sensible default SQL generation, with none of those problems and without even requiring a Java model (though mapping is done easily, if and when you actually need it). If you know even a little SQL, you already know enough to be productive with SQLDataSources.
If youâ€re at all familiar with the SmartClient reference architecture, you should be familiar with the concept of a DataSource. If you’re not familiar with DataSources, chapters 5, 7, and 8 of the Quick Start Guide explain them in-depth. The short version is that a single DataSource provides both client and server with metadata about your data model. On the client, this metadata is used to automate data binding (among other things). On the server, data access (among other things).
I’ll tend to refer to SmartClient documentation most of the time, but the approaches we’ll talk about apply to and are documented in both SmartClient and SmartGWT.
There are a handful of connectors that provide a subset of advanced features out of the box, including one for JPA / Hibernate, but there are good reasons to prefer SQLDataSource if youâ€re using a relational database to store your data.
Like other tools, you can have database tables created for you if you choose, including audit tables to automatically store changes made by users. The tables included with the sample ‘isomorphic†database in the SDK are generated tables, and you can use the Admin Console’s Import DataSources feature to generate your own tables from DataSources definitions (.ds.xml files).
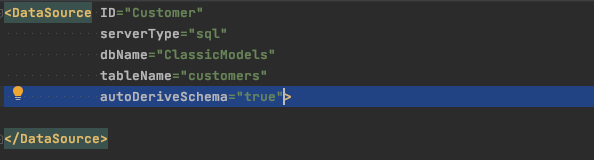
The application I was working with for my evaluation used an existing data model. I prefer to write my own DDL so I can control things like indexes and constraints, so I chose to start there. The fastest way to get started with an existing table is to use the DataSource autoDeriveSchema feature. Hereâ€s a DataSource configured for the ‘customers†table from the Classic Models schema:
Customer.ds.xml
Projects created using a Maven archetype will host the ClassicModels tables in the ClassicModels database, as shown here. SDK examples all use the default ‘isomorphic’ database, so you wouldn’t need the dbName attribute above, but sample DataSources will have names of the form CM_*.ds.xml. E.g., CM_Customer.ds.xml.
At runtime, your database metadata is used to “fill in the blanksâ€. Here, there are no fields so SmartClient will basically build the entire DataSource for you using names, types, lengths, constraints, etc. directly from your table definition.
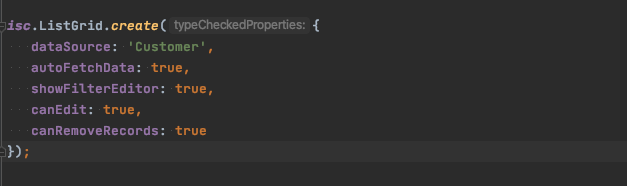
Assuming your running project is configured to host that sample database, you can use this DataSource right away by loading it and using it in a ListGrid.
index.jsp
Here we show some SmartClient JavaScript, but the equivalent SmartGWT code looks pretty much the same, except you of course also need a bunch of GWT boilerplate.
http://localhost:8080/
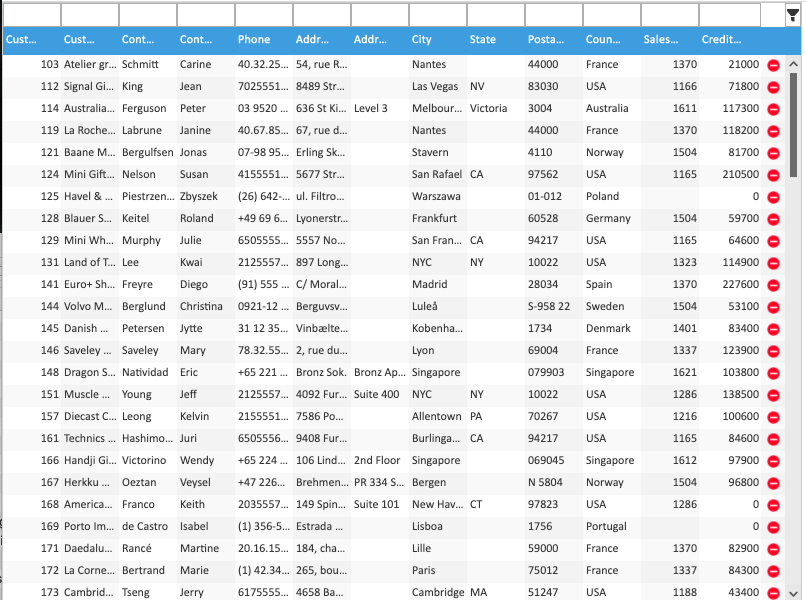
And thatâ€s it. With 12 lines (including formatting) of reusable configuration and code, you have a fully functioning client and server that queries your database for you and lists the result, and the user is able to filter, sort, group, edit, and delete records with validation. This example only shows a grid, but this one-liner DataSource is also ready accept requests from any of SmartGWT’s other databound components, feeding validation errors back to complex forms, providing results for ComboBoxes, or even filter on arbitrary AdvancedCriteria from a FilterBuilder. Bonus, you didn’t have to do anything to protect against SQL injection. In the project I outlined above, I found that I could eliminate a lot of server code, make it more secure, and add significant features while I was at it, with as little as a single line of XML.
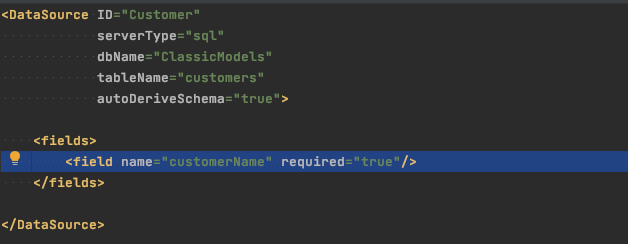
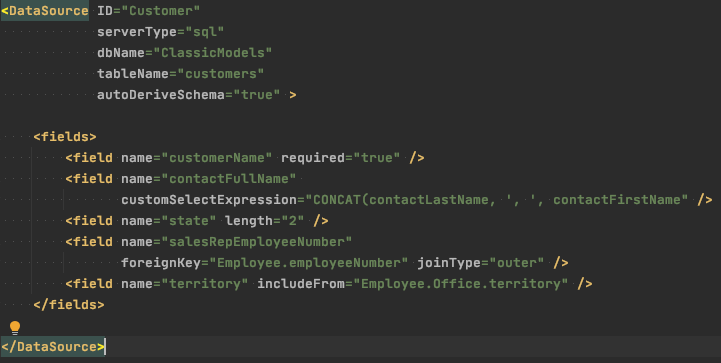
Of course there was a lot more to the application than what I’ve demonstrated with the pretend snippet above. You might never need to do anything else to a DataSource like this one, but I was going to have to augment or override at least some of it. Youâ€d want to mark required fields as such, for example. This is easy to do.
Notice there is no explicit definition for state, postalCode, and so on – these other fields are still derived completely from database metadata. Notice also that we donâ€t define the customerName field completely either – type, length, etc. are all missing from the explicit definition but autoDeriveSchema continues to fill in the blanks. You can override some or all of that derived metadata selectively too, if you choose. The state column on the database is actually a VARCHAR(50), for example, but you can pretty easily limit input to 2 characters (enforced on both the client and server).
This is all pretty powerful, and the XML definition is in a very accessible format thatâ€s easy for anyone to read and understand. But so far, weâ€ve been looking at the simplest possible case. What happens when you need to do more?
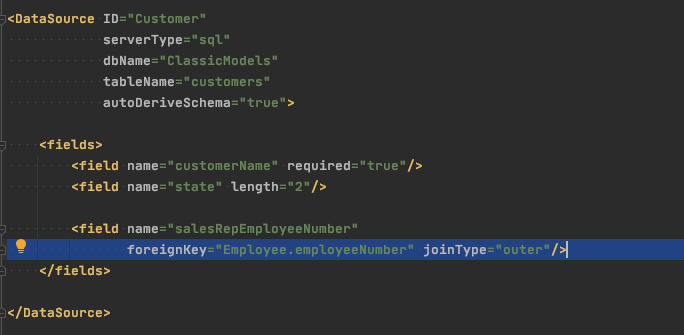
Here we define an explicit foreignKey attribute (which actually was also present in the derived examples, you just didnâ€t see it). You can pretty easily add columns from related tables, causing SmartClient to generate a SELECT statement that uses a JOIN to obtain the result. You can influence the way the JOIN is created, and even traverse relationships to retrieve data from a table 2 or more joins away.
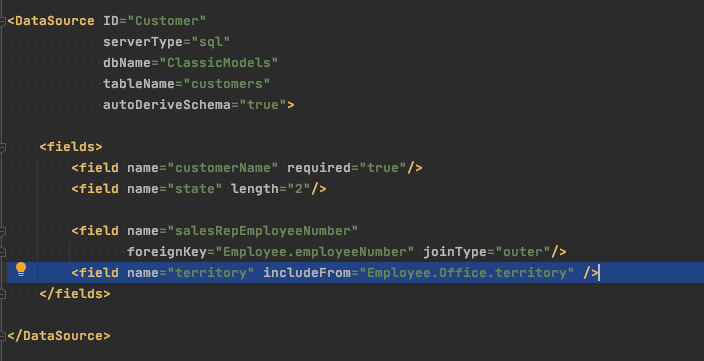
Here we add a territory field and take its value from the Office that the Customerâ€s salesRep is assigned to, by way of an OUTER JOIN involving 3 tables (Employee and Office definitions not shown for brevity). This “just works” without writing any SQL, or even a single line of Java code to create a statement and execute it. The ListGrid sample code shown above will simply display the data pulled from the related tables, with no change in the client-side code.
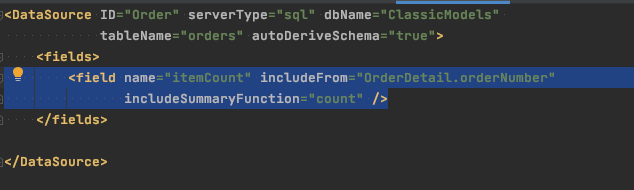
Grouping and aggregations can be handled for you with the same declarative style, or on request if you prefer.
I don’t know of any other platform that does so much for you and reduces complexity at the same time. Think for a minute about everything we’re able to do here, with just a few lines of XML declaration and a tiny block of JavaScript. Play around with your own schemas using a sample project and see for yourself, because we’re only scratching the surface here. Next time, we’ll review some of the very simple techniques that unlock even more power and flexibility.
I hear a lot that I should use something like JPAQL for what it’s good at, and then back away to SQL when I have something a little more complex. I think I showed last time that SQLDataSource is equally capable (if not more so) of generating simple SQL statements. The difference with SQLDataSource is, I can use the same, simplified approach to handle statements of any complexity. I can even let the framework generate some or most of the SQL, and then customize just the parts I need to.
For example, if all I want is to calculate a column value using a SQL expression, I can add a field to represent it and include an attribute containing the expression. The framework will generate the rest of the statement as usual. This works the way you’d expect for select, insert, update, delete, and even for criteria.
You can also combine your SQL expressions with Velocity expressions to be evaluated at runtime. You can put almost whatever you want into a context variable, but the framework provides a number of frequently used variables out of the box that cover the common cases.
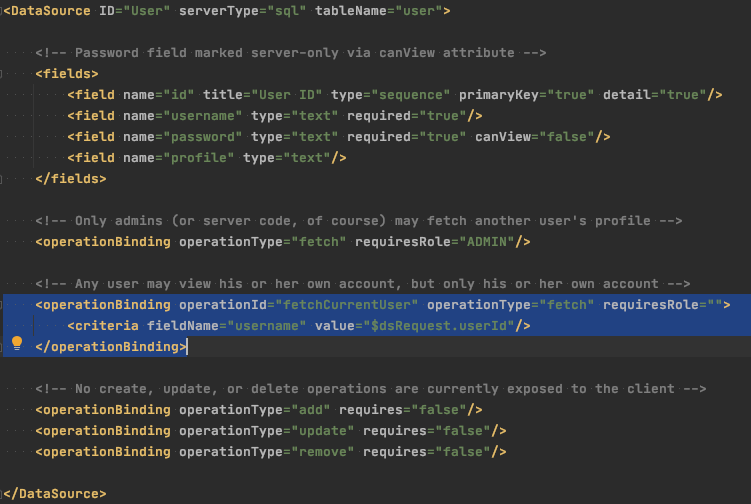
Here is an example of a pattern I use frequently for user authorization & record-level security. In this case, I want to fetch the currently authenticated User profile and UserRoles from related DataSources. Take a look at this fetchCurrentUser operation binding.
User.ds.xml
It forces the currently authenticated user’s userId (provided by the Servlet container and made available on dsRequest as a matter of convenience) into the WHERE clause, so that an authenticated user can only ever see their own profile (with a little help from declarative security). With no other criteria supplied, the result would look something like this.
SELECT id, username, password, profile FROM user WHERE username = ‘bill@isomorphic.com’ AND (1 = 1);
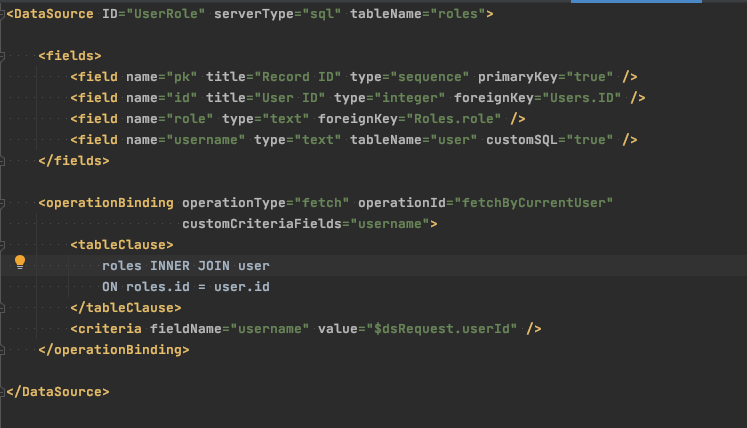
I use the same technique in UserRole to force the username in fetchByCurrentUser, but this operation also shows a little SQL Templating in action for customization of the FROM clause.
UserRole.ds.xml
I could have just as easily added the username filter by instead using a whereClause element with a $defaultWhereClause expression to the same effect.
SELECT pk, id, role, username FROM userRole WHERE username = ‘bill@isomorphic.com’ AND (1=1);
Or perhaps more appropriately in this case, just ignore additional criteria altogether:
SELECT pk, id, role, username FROM userRole WHERE username = ‘bill@isomorphic.com’;
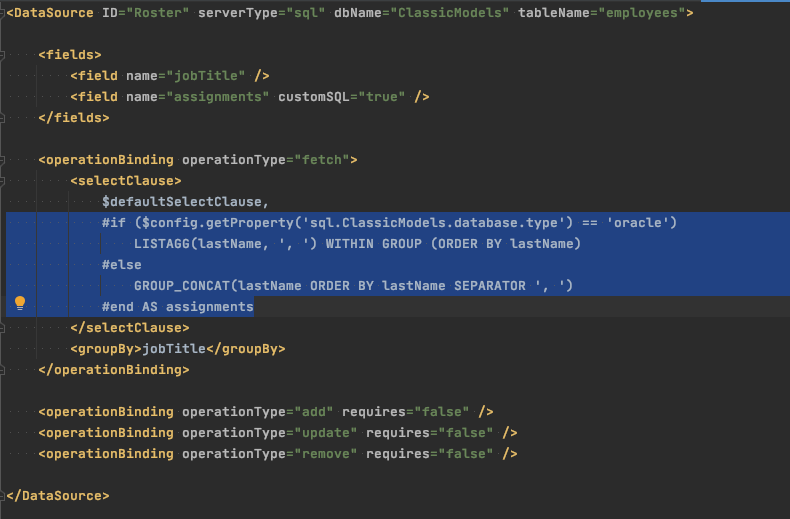
Maybe you’d like to use a database-specific function in your customization, depending on which database is deployed. Here I’ve made up an example Roster DataSource that illustrates one easy way to do so, using a Velocity conditional on another context variable provided by the framework. If we see that the app is configured for Oracle, we’ll use LIST_AGG, otherwise GROUP_CONCAT.
Roster.ds.xml
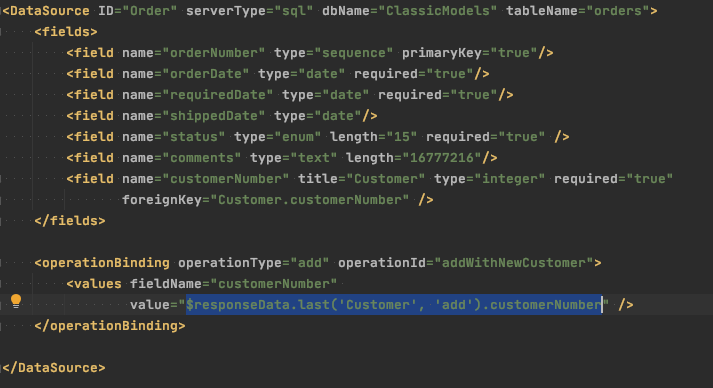
Keep looking, and you’ll find that all kinds of things you used to do yourself take very little effort using the same techniques. It’s very common, for example, to have one request depend on the response / result of another. Consider the creation of a new Customer record at the time they create their first Order, where you need the auto-assigned customerNumber before you can add the Order record.
I’ve seen a handful of projects attempt this kind of thing from client-side callbacks, which aside from being hard to look at requires 2 trips to the server and runs in separate transactions. That’s probably not what you really want, so SmartClient includes a feature that allows Transaction Chaining using the same declarative style (and even allows limited access to the same feature from client code with no configuration).
Occasionally though, none of these approaches provide quite enough flexibility to do exactly what you need. In that case, you can effectively extend SQL generation to fit your requirement with a single well-placed call to addToTemplateContext, as I alluded to earlier. Note that as in the example above, this can include calls to methods on classes you provide. And you can always just fall back to completely custom SQL, as I sometimes do to execute UNION queries or stored procedures.
Note that the use of customSQL necessarily disables a handful of very useful automatic framework features (paging, client component caches, etc.) so generally try to use another technique if you can.
I really could go on and on like this, manipulating SQL generation by adding an element here and an attribute there, but at some point you’ll want to do something that just can’t be handled with configuration alone.
I remember once having what seemed like a tricky situation, where I had to integrate with a document generation server whenever data from any one of four different DataSources was modified. The trick was, any of them could be modified in any combination, and I only wanted to generate the document once per transaction. As it turned out, I only had to write a few lines of code to keep track of a request attribute and check it in a callback fired by the framework when the transaction was complete.
Another time, I was working with a client using a FilterBuilder to allow their users to create very advanced criteria against a reporting database. These structures were very large and reasonably complicated, so they wanted to offload that processing to a reporting queue they’d already built. In the end, they needed no more than a few lines of code to pull off the integration, using another SQLDataSource to hold a request that included the complete SQL statement to be picked up by the reporting listener.
Need the actual JDBC connection for some truly unusual edge case? I’ve never needed it myself, but a colleague once used it to turn on and off a particular kind of caching on the fly for a particular transaction.
Your own application is unique, but I’m pretty confident that you can do more with less using some of these techniques and others that will have to wait for another day. Let us know on the forums if you have something you’d like to see covered!
In the last few months, we’ve been busy adding a whole new set of amazing features that will be available in the next release of SmartClient and SmartGWT.
We have already announced some fantastic additions to the framework in our previous posts (Part 1 / Part 2 ), and now there’s even more to extend the power and flexibility of SmartClient and SmartGWT!
This post shares just another taste of some of the new enhancements we have made recently.
FacetChart Databindingand Improvements
Historically, Charts have had their data values set by using the SetData() and updateData() APIs to set a static view of the chart.
In release 13.0, we’ve enhanced FacetChart to be a DataBoundComponent. The new features support a fetchData API that takes criteria and other DSRequest settings (like sorts), just like grids do, and will perform local filtering of data if criteria changes. So you can now easily create a drill-down interface that doesn’t require server contact.
OpenFin enables you to build multi-window desktop apps that look and feel just like natively installed apps so you can maximize your desktop real estate. Your windows can sit anywhere on the desktop, with or without frames. Apps you don’t actively watch can be minimized and automatically pop up when needed.
In collaboration with one of the world’s largest banks, our support for OpenFin means you can now create desktop applications that can open windows on multiple monitors.
Sharper Imagery
We’ve massively improved the quality of our internal imagery, so no matter how much you zoom in, you’ll still get the crisp, clean, seamless image view that you need.
SplitPane AutoNavigate
SplitPane component just got smarter. Using an “Auto-navigation” approach, SplitPane analyzes the controls placed in each pane and the DataSources they are bound to. It then automatically navigates between panes at the right time based on the actions that you take.
If you want to see what’s available in V13.0, download the V13.0 Pre-Release from our Downloads page.
If you want to upgrade early to V13.0, upgrade discounts are available based on your last license purchase date. View our License FAQs for more details, or contact us to discuss your upgrade options.
We are proud and pleased to announce that V13.0 of SmartClient and SmartGWT is officially here, with tons of fantastic new features. We’re sure you’ll agree it was worth the wait.
Some of the great features we have added to V13.0 are:
Once you have purchased your upgrade, Download Release 13.0 to get started (don’t forget to log in first)!
As always, please send us any bug reports or feedback in the Forums. Please be clear about what product and version you’re using when reporting issues, including the exact date of the build.
Last week we talked to a Principal Scientist (let’s call him Ken) at one of the worlds largest pharmaceutical companies. Ken gave us some really great insight into why and how they use SmartClient.
Ken’s organization provides software support (at varying levels) for thousands of in-house scientists scattered across “innumerable areas of expertise and roles”. Scientists come to his group when they need customized or unified solutions from software developers with domain knowledge.
The web applications that Ken’s team writes are obviously used by people who are highly educated. Their time is precious and their patience low. They demand “solutions that are highly sophisticated“, and they have “uncompromised expectations on ease-of-use.”  They “have many ideas, theories, and hypothesis that they want to explore”, so there is a long list of web applications to be developed, and also a long list of feature requests raised as their hypothesis unfold. Their work also generates and requires analysis of “huge volumes of data“.
For Ken, these demands meant he needed a platform that:
Can handle volume data from both performance and a usability perspectives
Has intuitive, high productivity UI components
Supports rapid development of web applications
Ken’s Results
With several years experience using SmartClient, Ken said:
I really like Smartclient because I can create new solutions quickly and then easily adapt to user’s feature requests as they evolve because it’s usually only a matter of re-configuring how I’m creating Smartclient objects. I don’t need to be too careful about collecting all possible use-cases up front because when they come to a new understanding of their own expectations, I don’t need to tell them that we’d need to change technologies to deliver their new ideas.
ListGrid, FormItem, and DynamicForm are the key widgets I turn to.
I also highly value the support forum. I imagine that my needs which are sometimes off the beaten track, so I highly value the rapid turnaround on enhancements, bug fixes and/or suggestions.
Here are just a few of the solutions Ken’s team built this year (note that all of these are leveraging our new ‘Tahoe‘ skin):
#1 Bulk Data Handling – “PPB Editor”
The “PPB Editor†(you can think of it as an electronic lab notebook) was written to enable scientists to rapidly load bulk data into a 3rd party data storage solution. The 3rd party had provided their own GUI, but it was too tedious to use at the scale the scientists required. It also didn’t match the scientist’s workflow. Furthermore, by writing their own interface, they have a convenient place to implement their own business rules (e.g., “autocalculators†and validation) to help people conform the raw data they collect to expectations set by the business and to support analytics. In particular, SmartClient helped with the following:
Binding to Datasources extremely quickly
ListGrid Expanding rows capabilities to allow additional information to be accessed without adding an unmanageable number of columns
FormItem was also a key feature  particularly since a class can be defined once and reused in both ListGrid and DynamicForm contexts. This meant that in their bulk editor, they can leverage multiple widgets to update the same data – saving much development effort and providing the scientists with the optimal UI.
The “Mylo†tool is for analytics  to help scientists find and/or explore new design ideas with experimental data previously collected. This application required the depth of functionality offered by SmartClient components. The following were critical:
The “Plate Layout†tool came about when a scientist described an upcoming technical challenge to Ken. Ken then created a GUI in less than one day that the scientist could use to test a hypothesis.
For Ken, the ability to rapidly develop web applications makes SmartClient indispensable in the pharmaceutical research and development environment.
Developing IT solutions to support research for new, more effective and efficient treatments for heart and lung disease.
Royal Brompton & Harefield NHS Foundation Trust is a partnership of two specialist hospitals, known throughout the world for their expertise, standard of care, and research success.  RBH has achieved incredible things: performing the first successful heart and lung transplant in Britain, implanting the first coronary stent, and pioneering intricate heart surgery for newborn infants. Countless lives have been saved, diseases prevented and lives extended.
However, the technical support for the research process was – until more recently – ad-hoc and inconsistent. Research data was often collected on paper and rekeyed into spreadsheets, or stored in one-off databases. This led to manual labor processes, data availability delays, and data accessibility problems. Analysis was also difficult and inefficient as data was stored in disparate locations, and a lack of tools necessitated custom SQL reports to be written.
Steven Collins is the IT lead at CRC (Cardiovascular Research Centre). With Smart GWT as the core technology, Steven and his team his team has made huge improvements. To highlight just a few:
Leveraged the rich Smart GWT validation features to prevent all mistakes during data entry
Used the DataSource XML Generator to combine data across studies, and with patient information as it is captured over time
Empowered researchers (via Dynamic Data Filtering) to create very complex queries (e.g. tree / nested, and, or, not) directly through the UI – without having to learn SQL.
Steven’s latest solution at CRC is the ‘Cardiovascular Research Centre Database Internal Web Portal’. It makes available all research data from all projects, available through a web portal. The CRC has many research studies going on at any given time, and data gathered in one study can actually be useful in others. Combining data across studies, and with patient information as it is captured over time (for example, medical events, doctor visits and reports) has provided invaluable insights into ongoing benefits and outcomes of treatments.
Learn how Steve and his team at Royal Brompton & Harefield NHS Foundation Trust have leveraged Smart GWT to achieve all this and more.
We often get asked about the difference between SmartClient and Smart GWT. The answer is: ‘not much‘.
When you’re running SmartGWT, you’re also running SmartClient
When you are running SmartGWT, you are also running SmartClient. You are using SmartClient’s widgets, data binding, browser compatibility, etc. See the SmartClient vs SmartGWT architecture diagrams below:
As you can see, we only use the tiniest sliver of GWT – just the GWT compiler. The GWT compiler translates your application code to JavaScript, and your translated application code then calls SmartClient APIs.
With the management of GWT transferred from Google to a “Steering Committee”, and the lack of a GWT release in the past couple of years, we get asked a bunch of questions about the long term impact of GWT on Smart GWT. Will we keep developing Smart GWT? Will Smart GWT continue to support the latest browsers? etc.
What happens with GWT is irrelevant to Smart GWT
The fact of the matter is that what happens with GWT is irrelevant to Smart GWT. The problems that people anticipate from core GWT development slowing down do not apply to people using SmartGWT:
if the pace of widget development in GWT slows down, doesn’t matter: SmartGWT’s widgets will continue to be rapidly improved
if GWT widgets stop supporting the latest browsers, doesn’t matter: SmartGWT’s widgets will continue to support the latest browsers
if GWT’s recommend data binding approach continues to change radically with new releases, doesn’t matter: you’re using SmartGWT’s data binding
We literally cannot help but continue to improve SmartGWT
We also get asked: will Isomorphic stop emphasizing SmartGWT, and focus more on SmartClient? This also is a non-issue, because, the way we develop new SmartGWT features is that we develop new features for SmartClient, and then an automated process takes the new SmartClient documentation and generates new SmartGWT APIs from it. So we literally cannot help but continue to improve SmartGWT, as we build more SmartClient features.
We are excited to share with you some of our upcoming features due to be launched in V13.0 of SmartClient and SmartGWT.
Open API Support
Integrating with other technologies just got a lot simpler!!!
We’ve always made it pretty simple. If you’re using our technology, whenever you define a DataSource, we automatically provide a REST-based interface to it. This means you can easily integrate with automated processes (such as reporting) or even provide access to third-party UIs (such as a native mobile applications).
Now, we’ve embraced Open API, which is an industry-standard way of describing server APIs, so you can access them with simple XML or JSON messages.
In 13.0, with no effort required at all, you can get a standard Open API descriptor explaining the REST interface to your DataSource. It’s available by simply appending openapi.yaml to the URL where you have registered your RESTHandler servlet.
The Open API descriptor is quite rich, incorporating your field types, validator definitions, and other standard DataSource metadata to provide a complete descriptor.
Your customers will be able to use Open API tools to get connected faster than ever!
Modern UIs going for the “minimalist” look often have scrollbars that aren’t even shown until you start scrolling, which nicely reduces “visual noise”.
Now in 13.0, we automatically detect if your browser hides scrollbars by default, and we match that behavior.
If you’re a big fan of our custom scrollbars – which are designed to match the skin you’re using – don’t worry! You can reverse this change with a single boolean setting autoHideScrollbars.
To give you an idea of how this looks, take a look at our new Reify tool with and without scrollbars – much cleaner!
See how the scrollbars come into view and are manageable as soon as you need them!
CSS Editors Your end users can now customize the look & feel of applications you deliver!
Our platform is often chosen because it is so flexible, and people want to offer their end users extreme customization options: everything from saving dashboards full of deeply customized grids, to the ability to create queries that only analytics platforms can usually do.
In that spirit, we are introducing powerful tools for editing the appearance of applications:
Our StyleEditor lets you edit all the basics of a CSS style: colors, borders, padding, fonts, etc
Client-side Authentication & Roles Simulator for Prototyping
The server team hasn’t set up authentication and roles yet, so there’s no way to test that stuff, right?
Wrong!!!
Similar to Client-Only DataSources, we now offer a Client-side Authentication & Roles system.
You just call client-side APIs like Authentication.setRoles(), and then:
DataSources will disallow operations if you don’t have the role (set via operationBinding.requiresRole)
Component fields that should not be visible won’t be (set via DataSourceField.editRequiresRole for example)
UI components that should disappear or be disabled based on roles can declare this (via button.visibleWhen for instance)
Then, when you have a real authentication system, you just make the call to setRoles() with the real set of authorized roles and everything just works with no code changes required.
This is just another way that Isomorphic helps you create great parallelism between your UI team and your server team, so your projects are delivered early! Take a look at the sample here.
This system also makes it easy to test client-side security rules in isolation, so you can rapidly figure out where the bugs are.
Finally, a quick note: obviously this system is not for actually enforcing security – that needs to be done on the server. However, the settings noted above, requiresRole, also perform the actual enforcement when used with our server framework, in a server DataSource descriptor (.ds.xml file).
Custom Event Widgets for Calendars
The Calendar component can now show an arbitrary UI component instead of the built-in events. You can make your events interactive, or allow them to be edited directly instead of in a pop-up dialog by making use of showEventCanvasComponents.
No matter what content you want to create, (Links to other URL’s, imagery, grids and/or forms), they can all be embedded in a calendar event, making calendars flexible enough for any features you will ever need!
The calendar has also gained a new layout mode: events can be stacked within days rather than being rendered at specific times on a day. This allows the Calendar to also function as a kind of “to-do” list, where events are associated with a day but not with a particular time slot.
This is just a taste of some of the powerful new features that will be available in V13.0 Keep an eye out for more about what’s coming up in our next major release.
If you want to take a look at what’s available in V13.0, download the V13.0 Pre-Release from our Downloads page.
If you want to upgrade early to V13.0, upgrade discounts are available and are based on the date of your last license purchase. View our License FAQs for more details or contact us to discuss your upgrade options.
Following on from our last feature post for V13.0, welcome to our second installment of even more fantastic capabilities that will be available in the next release of SmartClient and SmartGWT.
Persistent Hovers
Sometimes, a hover is so useful you want it to stick around!
Now, you can just use the focusHoverKey setting to provide a keyboard shortcut for a user to “stick” a hover in place. The hover becomes a floating window that the user can interact with or dismiss.
Improved Client-Only DataSource
Client-Only DataSources provide an efficient way to prototype the UI while the server-side guys are still working to get things going. When you build a UI that uses Client-Only DataSources, you can swap in the real DataSources when they are ready, and nothing about the UI needs to be changed – it just works.
Now in 13.0, Client-Only DataSources have “grown up” to be able to mimic all of the powerful features of our server-side framework. You can now:
Define relationships between clientOnly DataSources with the foreignKey attribute
Use includeFrom to pull values from related DataSources, the equivalent of a SQL JOIN
Use aggregation features to compute sums, averages, maxes or distinct values – like SQL’s SUM, GROUP BY and SELECT DISTINCT
Use aggregation even with related DataSources, for use cases like getting the total cost of all items that are related to an order
Basically, all of the Server Summaries features discussed below now work with ClientOnly DataSources.
Server Summaries Enhancements
Our server framework can do advanced aggregation from just simple declarations, and can even do it on the fly!
A series of new samples demonstrates the power of aggregation and ways to customize it.
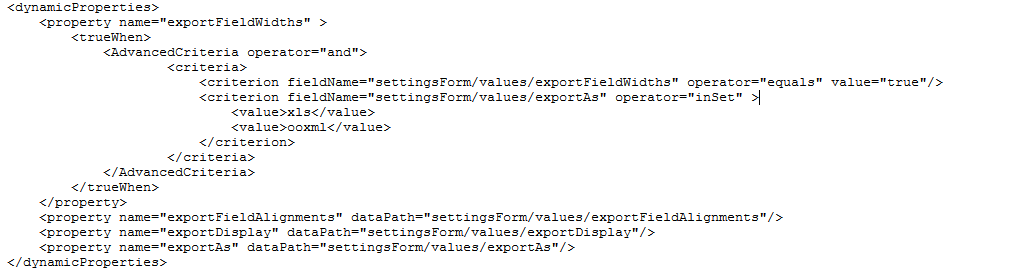
The DynamicProperties system allows you to declare that a component setting depends on data in surrounding components, including user-entered data.
With this new support, there are now literally thousands of boolean settings on components: anything from listGrid.showFilterEditor to comboBoxItem.allowEmptyValue, that can be succinctly declared to depend on user-entered data, without having to write event handling code.
In this example, you can see a form for configuring an export for a grid. There’s no code, no event handling, anywhere in this sample – it’s all done via simple declarations, and easy for a non-programmer to understand.
TIP: You can already declare whether components are visible, enabled, or editable via the visibleWhen and enabledWhen properties.
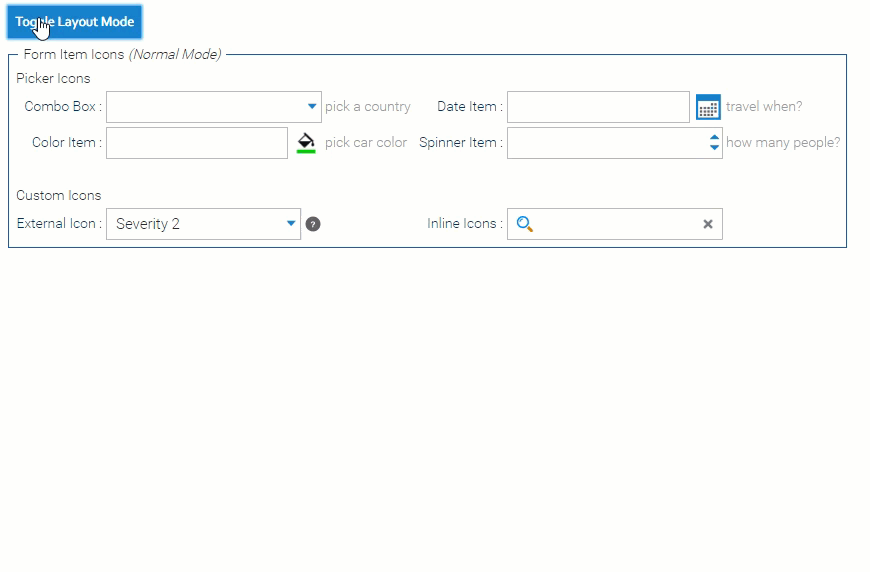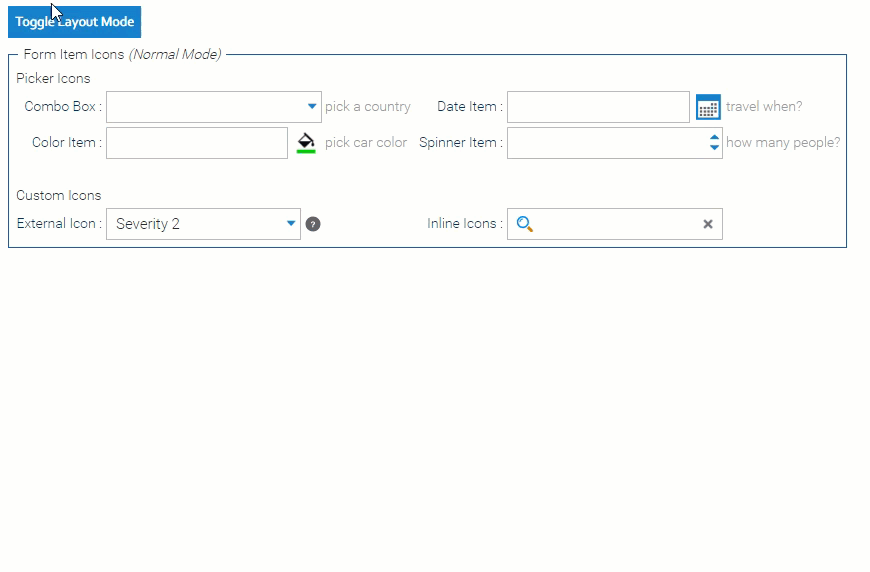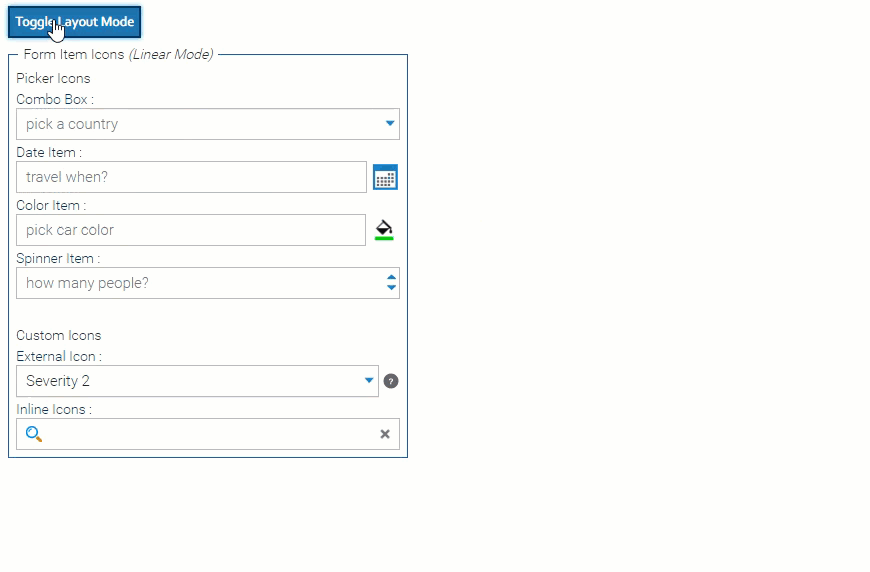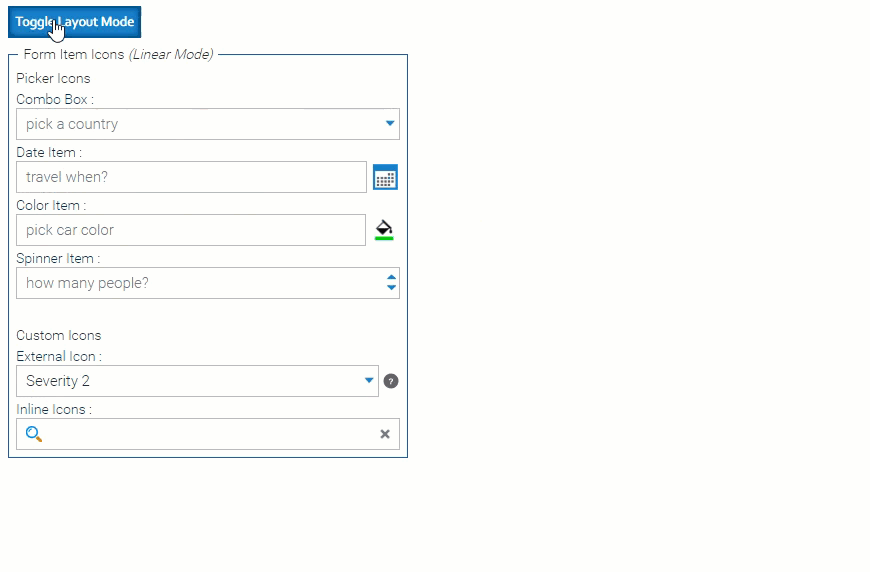
Adaptive Forms It’s now much easier to design a form that works well on both desktop and mobile!
Just design your form with the desktop in mind, and turn on the new “linear mode” for mobile.
In linear mode, your form will render with one form control per row, ignoring all the size & placement settings that are typically used when designing a multi-column form for desktop use.
If you still want to tweak your form for mobile – for example, you have two very short text fields that can appear adjacent, even on a narrow phone screen – you still can. You use the same settings you usually do, but prefix them with linear.
For example, startRow -> linearStartRow.
Take a look a the full sample to see how we do this.
Infinite Scroll Repeating Components
Our grids allow you to place any kind of component you want into cells or rows, including completely replacing the default row rendering. This is an extremelypowerful feature that allows you to use a grid to contain any kind of repeating widget, for any size of data.
Check out this new sample, showing a specialized rendering of each row, including a non-columnar data layout, the ability to edit data, and actions that are enabled or disabled based on data values in the row.
It doesn’t even look like a grid! But you have all the power of the grid, with a completely different presentation for rows.
If you want to take a look at what’s available in V13.0, download the V13.0 Pre-Release from our Downloads page.
If you want to upgrade early to V13.0, upgrade discounts are available and are based on the date of your last license purchase. View our License FAQs for more details or contact us to discuss your upgrade options.
As Isomorphic’s CTO, I’m typically brought in to save projects that have gone off the rails. So I’ve got 20 years experience in vigorous facepalming.
Very often, we are approached by companies that started with another technology and have hit a dead end. Typically, we end up inserting our more sophisticated components into the middle of existing screens, and then the customer migrates to our technology over time, slowly, painstakingly cutting through the spaghetti code they had to write because they didn’t start with us.
Whenever this happens, I always try to figure out how the customer ended up using some other technology rather than starting with ours.
Sometimes, they just didn’t do an evaluation at all. People blindly follow trends, and developers are just as guilty of this as anyone else.
However, sometimes, we run across a customer that did evaluate our technology, and decided against using it, only to regret that decision later.
This happens because people evaluate software in the wrong way.
I’ll explain what I mean with a story.
Let’s say you are trying to figure out which vehicle would be best to use when entering an endurance race.
As a first step, you try to figure out if you can get the vehicle to go 20 feet. A reasonable first test, right? Clearly a vehicle that can win an endurance race must be able to go 20 feet with ease.
So here are the two possibilities you’re evaluating:
the vehicle that won Le Mans last year
.. or ..
a tricycle
After testing them out, you determine that both can go 20 feet. However, the vehicle that won Le Mans gets poor marks because:
You had to find the keys
You had to open the car door
You had to turn the key to start the engine
You had to shift into gear
It wasn’t obvious which pedal to push to go
So clearly, the tricycle is the better choice for Le Mans, and the next step is to commit to the tricycle and see how fast and efficient it can be made.
Except, obviously not, right?
So what was the mistake?
The mistake was: you didn’t test whether the vehicle could do well in Le Mans, you tested whether it could go 20 feet.
And if the task is going 20 feet, then a tricycle looks pretty damn good, because in general, a technology is going to look really good when it’s doing the most that it was designed to do, and is going to look not as good if it’s asked to do something that’s a little too simple.
Now you may be thinking: that’s ridiculous! No one makes decisions that way.
Ah but they do. It’s just that, when evaluating software, things are more complex, and it’s not as blindingly obvious that you are comparing a race car to a tricycle.
Here are a few real-life stories of competitive evaluations where our technology “lost”, only to have the customer come back to us later:
Comparing grids by connecting to a rudimentary data service
Multiple times, we’ve had evaluators try to compare grid components by connecting to some kind of free public data service, or to a data service created as a tutorial. Invariably, these services are very basic: they don’t support paging, advanced use of criteria, sorting, editing of any kind, or any other advanced features, even though the final application will definitely be using such features.
In this type of evaluation, our technology is made to look bad because you have to turn a bunch of features off to deal with such an underpowered service, and because you have to adapt to a poorly designed protocol that is not built for an enterprise UI.
As a result, the final UI is about the same with either technology, because, again, they turned all the good stuff off. Since our technology was a little harder to set up, the simpler and less capable technology is chosen. Later, the customer realizes that they really do need those advanced features, and it would be a nightmare to try to rebuild them based on the simpler technology. And that’s when they call us back.
Building a Login Dialog
This evaluation is flawed first of all because our best practices tell you to use a plain HTML login page. This allows you to begin caching your application while the user is logging in. We even provide such a starter login page, complete with caching logic.
But the bigger issue with this evaluation is that it’s too simple. Form components for enterprise apps are distinguished by their advanced layout behaviors, advanced data-binding support, and wide range of controls (like our date range editors).
The login dialog is the one place where none of these features are useful: you pretty much have the entire screen for two simple text fields, and data-binding doesn’t apply.
Instead, this evaluation should have focused on building a typical form for a business application, complete with complex validation rules, typeahead and other productivity features. Then, they would have found that, with our technology, everything is already set up how you would want it, and we have made the hard things really simple.
Focusing on replicating a “pretty” design
People like UIs to look good, and in a demo of UI components, one of the easiest ways to look good is to create a very “spacious” design, where controls are oversized, a huge amount of padding is used, and enormous, attractively-styled error messages appear in the middle of the form layout, right under the item that has the error.
The problem here is that in enterprise apps, space is at a premium, and there are multiple panes and components on the screen all needing as much space as possible. The “oversized” look works for a simple web page, but not for an enterprise app.
Our platform correctly defaults to showing validation errors as just a compact error icon, which avoids misaligning typical two-column forms, and avoids creating scrolling due the form growing in size. In trying to match a design featuring oversized controls and gigantic error messages, the evaluator is trying to replicate an appearance which you do not want.
It’s straightforward to get the spacious look with our technology, for the rare case that it makes sense. However, in one example of this kind of botched evaluation, the design team worried that they might be “fighting” against our platform’s default look-and-feel choices, and went with another technology. They came back about 8 months later, having scrapped the old design after criticism of early prototypes, and began using our default look and feel with some customized colors and fonts.
Trying to apply CSS-based layout techniques
Extending on the above point, multiple evaluators have tried to copy CSS-based layouts from elsewhere, and found that this doesn’t work because our layouts are more than just CSS. CSS-based layouts simply cannot do what our platform can do, in terms of features like Adaptive Width (sample).
So called CSS-based “mobile adaptive” frameworks simply switch to a completely different layout for smaller screens, rather than maximally taking advantage of screen space, as our platform can.
So here, a strength is perceived as a weakness, and the evaluator decides that a crude CSS-based layout system is the better choice.
In one instance, a few months later, a product manager called us up complaining that his developers were saying that certain layout behaviors were “impossible”, but he could see them right on our website! That ultimately led to switching back to our technology.
So how should you evaluate software like ours? Our advice is to take the most difficult and complicated screen you have, the one where you’re not even sure how to approach it yet, and try to build that.
Think about what it means that we would advise this. We are the real deal; we don’t take shortcuts and we don’t fake things.
And finally, what are the consequences if you make a mistake, and choose an underpowered technology? Your product designers are repeatedly told that certain features would take too long to implement, so the scope has to be reduced. After a painfully long and badly delayed development process, in which the developers repeatedly try to re-create features which are already present in SmartClient, finally a 1.0 version shambles out the door.
This 1.0 version is like the tricycle at Le Mans: some kind of engine has been bolted onto the side, which belches smoke and has a tendency to slice off limbs, and the tricycle must be ridden at low speed or the wheels melt!
Meanwhile your competitors, who used our software, entered the race months ago with sleek, flexible, blazing fast vehicles.
Don’t be on Team Tricycle – use the right tool for the job!!
About 10 years ago, I was working for a Fortune 500 company whose primary line-of-business application was built using a homegrown framework that was loosely based on a Java Model 2 / MVC type of architecture.
I’d been asked to come up with a way to migrate away from that platform in phases and was looking at alternatives. We liked the idea of GWT at the time, and like many people, I found SmartGWT while I was evaluating various widget libraries. Right away, we were impressed by the depth and breadth of what the components could do out of the box (ListGrid comes to mind), but we pretty quickly realized that the server framework is equally powerful, if not more so.
At the time, Hibernate was considered the obvious choice for your persistence strategy, and a lot of people still feel that way. With respect, I think I’ll just say that even proponents of Hibernate will ask you to invest in a pretty steep learning curve to understand how to use it properly, and then say that you’ll probably still have to write at least some (if not most) of your own SQL.
Frankly, I’ve never been convinced that any ORM solves the so-called impedance mismatch problem anyway. And where is the improvement when you still need to know SQL, and now also the entire ORM system and the challenges that come with it? In my experience, these projects typically end up adding redundancy, complexity, and as often as not, some performance issue. Ask your Oracle DBA how he feels about it.
With SmartClient / SmartGWT, I got complete, declarative control over sensible default SQL generation, with none of those problems and without even requiring a Java model (though mapping is done easily, if and when you actually need it). If you know even a little SQL, you already know enough to be productive with SQLDataSources.
If you’re at all familiar with the SmartClient reference architecture, you should be familiar with the concept of a DataSource. If you’re not familiar with DataSources, chapters 5, 7, and 8 of the Quick Start Guide explain them in-depth. The short version is that a single DataSource provides both client and server with metadata about your data model. On the client, this metadata is used to automate data binding (among other things). On the server, data access (among other things).
I’ll tend to refer to SmartClient documentation most of the time, but the approaches we’ll talk about apply to and are documented in both SmartClient and SmartGWT.
There are a handful of connectors that provide a subset of advanced features out of the box, including one for JPA / Hibernate, but there are good reasons to prefer SQLDataSource if you’re using a relational database to store your data.
Like other tools, you can have database tables created for you if you choose, including audit tables to automatically store changes made by users. The tables included with the sample ‘isomorphic’ database in the SDK are generated tables, and you can use the Admin Console’s Import DataSources feature to generate your own tables from DataSources definitions (.ds.xml files).
The application I was working with for my evaluation used an existing data model. I prefer to write my own DDL so I can control things like indexes and constraints, so I chose to start there. The fastest way to get started with an existing table is to use the DataSource autoDeriveSchema feature. Here’s a DataSource configured for the ‘customers’ table from the Classic Models schema:
Customer.ds.xml
Projects created using a Maven archetype will host the ClassicModels tables in the ClassicModels database, as shown here. SDK examples all use the default ‘isomorphic’ database, so you wouldn’t need the dbName attribute above, but sample DataSources will have names of the form CM_*.ds.xml. E.g., CM_Customer.ds.xml.
At runtime, your database metadata is used to “fill in the blanksâ€Â. Here, there are no fields so SmartClient will basically build the entire DataSource for you using names, types, lengths, constraints, etc. directly from your table definition.
Assuming your running project is configured to host that sample database, you can use this DataSource right away by loading it and using it in a ListGrid.
index.jsp
Here we show some SmartClient JavaScript, but the equivalent SmartGWT code looks pretty much the same, except you of course also need a bunch of GWT boilerplate.
http://localhost:8080/
And that’s it. With 12 lines (including formatting) of reusable configuration and code, you have a fully functioning client and server that queries your database for you and lists the result, and the user is able to filter, sort, group, edit, and delete records with validation. This example only shows a grid, but this one-liner DataSource is also ready accept requests from any of SmartGWT’s other databound components, feeding validation errors back to complex forms, providing results for ComboBoxes, or even filter on arbitrary AdvancedCriteria from a FilterBuilder. Bonus, you didn’t have to do anything to protect against SQL injection. In the project I outlined above, I found that I could eliminate a lot of server code, make it more secure, and add significant features while I was at it, with as little as a single line of XML.
Of course there was a lot more to the application than what I’ve demonstrated with the pretend snippet above. You might never need to do anything else to a DataSource like this one, but I was going to have to augment or override at least some of it. You’d want to mark required fields as such, for example. This is easy to do.
Notice there is no explicit definition for state, postalCode, and so on – these other fields are still derived completely from database metadata. Notice also that we don’t define the customerName field completely either – type, length, etc. are all missing from the explicit definition but autoDeriveSchema continues to fill in the blanks. You can override some or all of that derived metadata selectively too, if you choose. The state column on the database is actually a VARCHAR(50), for example, but you can pretty easily limit input to 2 characters (enforced on both the client and server).
This is all pretty powerful, and the XML definition is in a very accessible format that’s easy for anyone to read and understand. But so far, we’ve been looking at the simplest possible case. What happens when you need to do more?
Here we define an explicit foreignKey attribute (which actually was also present in the derived examples, you just didn’t see it). You can pretty easily add columns from related tables, causing SmartClient to generate a SELECT statement that uses a JOIN to obtain the result. You can influence the way the JOIN is created, and even traverse relationships to retrieve data from a table 2 or more joins away.
Here we add a territory field and take its value from the Office that the Customer’s salesRep is assigned to, by way of an OUTER JOIN involving 3 tables (Employee and Office definitions not shown for brevity). This “just works” without writing any SQL, or even a single line of Java code to create a statement and execute it. The ListGrid sample code shown above will simply display the data pulled from the related tables, with no change in the client-side code.
Grouping and aggregations can be handled for you with the same declarative style, or on request if you prefer.
I don’t know of any other platform that does so much for you and reduces complexity at the same time. Think for a minute about everything we’re able to do here, with just a few lines of XML declaration and a tiny block of JavaScript. Play around with your own schemas using a sample project and see for yourself, because we’re only scratching the surface here. Next time, we’ll review some of the very simple techniques that unlock even more power and flexibility.
I hear a lot that I should use something like JPAQL for what it’s good at, and then back away to SQL when I have something a little more complex. I think I showed last time that SQLDataSource is equally capable (if not more so) of generating simple SQL statements. The difference with SQLDataSource is, I can use the same, simplified approach to handle statements of any complexity. I can even let the framework generate some or most of the SQL, and then customize just the parts I need to.
For example, if all I want is to calculate a column value using a SQL expression, I can add a field to represent it and include an attribute containing the expression. The framework will generate the rest of the statement as usual. This works the way you’d expect for select, insert, update, delete, and even for criteria.
You can also combine your SQL expressions with Velocity expressions to be evaluated at runtime. You can put almost whatever you want into a context variable, but the framework provides a number of frequently used variables out of the box that cover the common cases.
Here is an example of a pattern I use frequently for user authorization & record-level security. In this case, I want to fetch the currently authenticated User profile and UserRoles from related DataSources. Take a look at this fetchCurrentUser operation binding.
User.ds.xml
It forces the currently authenticated user’s userId (provided by the Servlet container and made available on dsRequest as a matter of convenience) into the WHERE clause, so that an authenticated user can only ever see their own profile (with a little help from declarative security). With no other criteria supplied, the result would look something like this.
SELECT id, username, password, profile FROM user WHERE username = ‘bill@isomorphic.com’ AND (1 = 1);
I use the same technique in UserRole to force the username in fetchByCurrentUser, but this operation also shows a little SQL Templating in action for customization of the FROM clause.
UserRole.ds.xml
I could have just as easily added the username filter by instead using a whereClause element with a $defaultWhereClause expression to the same effect.
SELECT pk, id, role, username FROM userRole WHERE username = ‘bill@isomorphic.com’ AND (1=1);
Or perhaps more appropriately in this case, just ignore additional criteria altogether:
SELECT pk, id, role, username FROM userRole WHERE username = ‘bill@isomorphic.com’;
Maybe you’d like to use a database-specific function in your customization, depending on which database is deployed. Here I’ve made up an example Roster DataSource that illustrates one easy way to do so, using a Velocity conditional on another context variable provided by the framework. If we see that the app is configured for Oracle, we’ll use LIST_AGG, otherwise GROUP_CONCAT.
Roster.ds.xml
Keep looking, and you’ll find that all kinds of things you used to do yourself take very little effort using the same techniques. It’s very common, for example, to have one request depend on the response / result of another. Consider the creation of a new Customer record at the time they create their first Order, where you need the auto-assigned customerNumber before you can add the Order record.
I’ve seen a handful of projects attempt this kind of thing from client-side callbacks, which aside from being hard to look at requires 2 trips to the server and runs in separate transactions. That’s probably not what you really want, so SmartClient includes a feature that allows Transaction Chaining using the same declarative style (and even allows limited access to the same feature from client code with no configuration).
Occasionally though, none of these approaches provide quite enough flexibility to do exactly what you need. In that case, you can effectively extend SQL generation to fit your requirement with a single well-placed call to addToTemplateContext, as I alluded to earlier. Note that as in the example above, this can include calls to methods on classes you provide. And you can always just fall back to completely custom SQL, as I sometimes do to execute UNION queries or stored procedures.
Note that the use of customSQL necessarily disables a handful of very useful automatic framework features (paging, client component caches, etc.) so generally try to use another technique if you can.
I really could go on and on like this, manipulating SQL generation by adding an element here and an attribute there, but at some point you’ll want to do something that just can’t be handled with configuration alone.
I remember once having what seemed like a tricky situation, where I had to integrate with a document generation server whenever data from any one of four different DataSources was modified. The trick was, any of them could be modified in any combination, and I only wanted to generate the document once per transaction. As it turned out, I only had to write a few lines of code to keep track of a request attribute and check it in a callback fired by the framework when the transaction was complete.
Another time, I was working with a client using a FilterBuilder to allow their users to create very advanced criteria against a reporting database. These structures were very large and reasonably complicated, so they wanted to offload that processing to a reporting queue they’d already built. In the end, they needed no more than a few lines of code to pull off the integration, using another SQLDataSource to hold a request that included the complete SQL statement to be picked up by the reporting listener.
Need the actual JDBC connection for some truly unusual edge case? I’ve never needed it myself, but a colleague once used it to turn on and off a particular kind of caching on the fly for a particular transaction.
Your own application is unique, but I’m pretty confident that you can do more with less using some of these techniques and others that will have to wait for another day. Let us know on the forums if you have something you’d like to see covered!





 s feature requests as they evolve because itâ€
s feature requests as they evolve because itâ€